Approach

PARL takes paired natural language instructions and demonstration trajectories as inputs. It recovers object-level concepts such as shapes and colors, and action concepts from the natural language. It then learns a planning-compatible model for object and action concepts. At test time, given novel instructions, it performs a combined high-level planning and low-level policy unrolling to output the next action to take.
Symbol Discovery
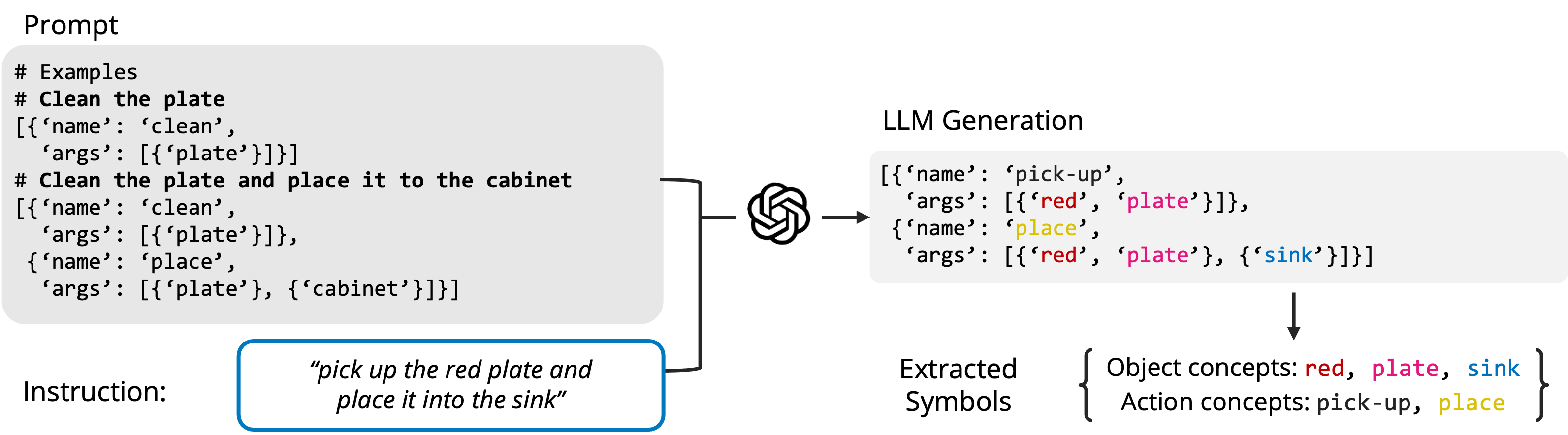
PARL prompts a pretrained large language model (LLM) to parse instructions into a symbolic formula. Next, we extract the object-level and action concepts from the formulas.
Planning-Compatible Model Learning
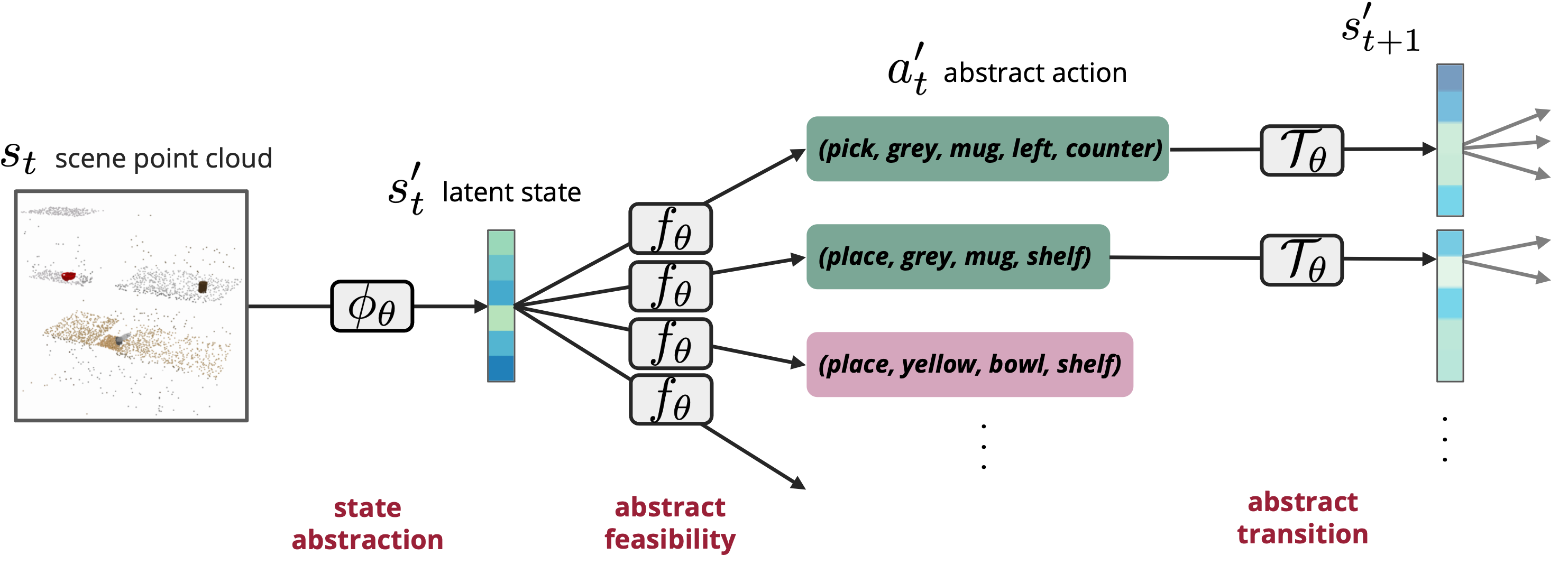
PARL grounds the discovered symbols using the demonstration data and interactions with the environment. We learn planning-compatible models, composed of (a) an object-level PCT encoder for extracting state abstractions and (b) an abstract transition Transformer for abstract transition and the feasibility prediction.
Generalizations
PARL generalizes (1) to scenarios with a different number of objects than those seen during training, (2) to unseen composition of action concepts and object concepts (e.g., generalizing from cleaning red plates and blue bowls to cleaning red bowls), (3) to unseen sequences of abstract actions, and (4) even to tasks that require a longer planning horizon.
BabyAI
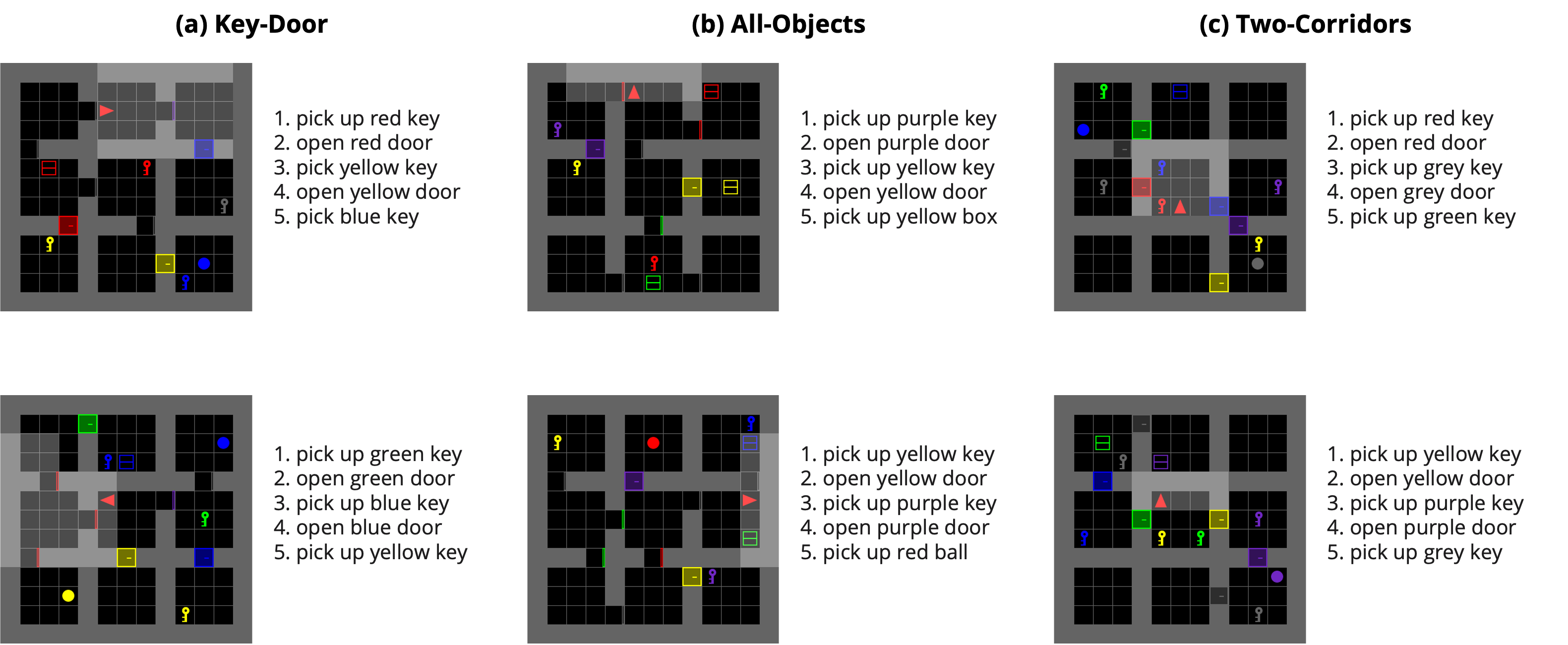
PARL can solve BabyAI tasks that requires a minimum of 5 abstract actions while only training on examples with at most 3 abstract actions. Each figure visualizes the initial state of the environment and the location of the agent (represented by the red arrow). On the right of each figure, the sequence of planned abstract actions is listed. The last abstract action in each list is the goal abstract action in the given language instruction.
Kitchen-Worlds
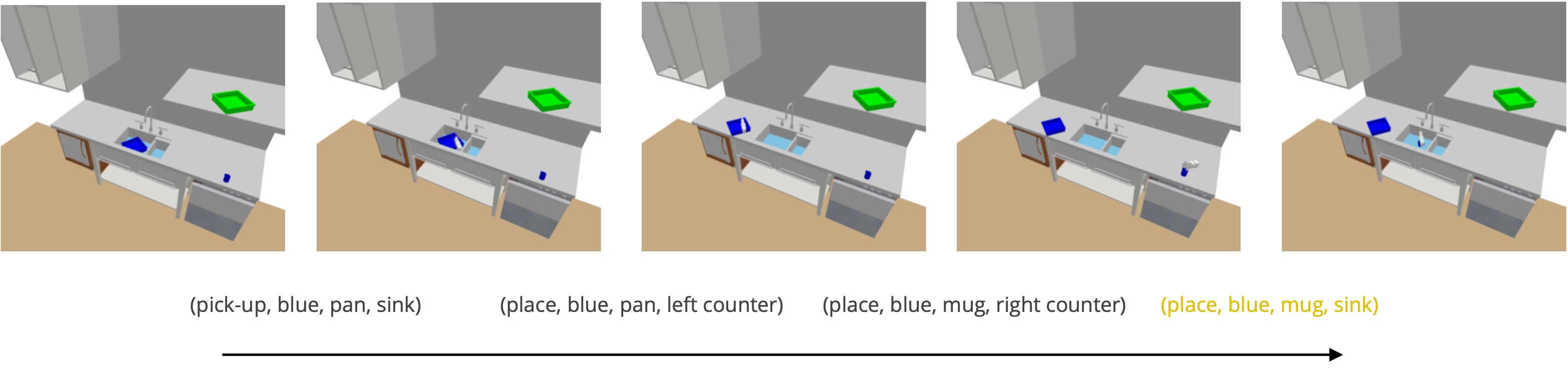
PARL can also work on more visually complex 3D environments. Given the language goal of placing blue mug in the sink, PARL can reason about the geometry of the environment and perform planning with learned abstract latent space to predict the sequence of abstract actions.